Contenuti
COME ACQUISTARE Internet Computer (ICP) IN BINANCE e ottenere un BONUS di €30

Acquista Internet Computer (ICP) su Binance

FASE 1: REGISTRAZIONE
IMPORTANTE: PER OTTENERE €30 a BTC quando ti iscrivi PER BINANCE, DO IT da questo link. CONFERMANDO LA TUA EMAIL, RICEVERAI LA RICOMPENSA.
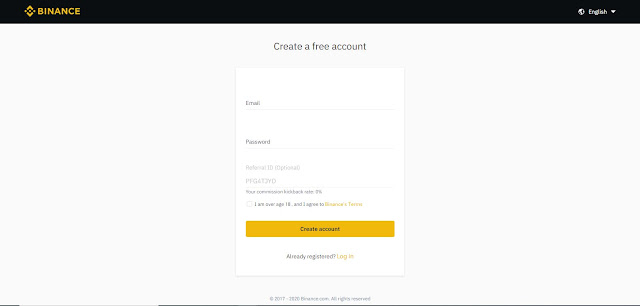
FASE 2: DEPOSITO FONDI

FASE 3: ACQUISIRE CRIPTOVALUTA

Perché acquistare Internet Computer (ICP)

Cos’è Internet Computer (ICP) ?
Internet Computer estende le funzionalità dell’Internet pubblica da una rete che collega miliardi di persone (tramite protocolli TCP / IP) a una piattaforma informatica pubblica che dà potere a milioni di sviluppatori e imprenditori (tramite il protocollo ICP).), Offrendo un nuovo modo rivoluzionario costruire. Servizi Internet aperti per il mercato di massa, piattaforme a livello di settore, siti Web e sistemi aziendali protetti e DeFi, il tutto senza la necessità di elaborazione legacy come servizi cloud centralizzati, database e firewall.
Il computer Internet viene creato utilizzando un protocollo decentralizzato (PKI) matematicamente sicuro, combinando la capacità di calcolo di migliaia di data center indipendenti in tutto il mondo in un ambiente informatico pubblico unificato e trasparente che opera alla velocità del web con capacità illimitata, consentendo agli imprenditori e sviluppatori per reinventare il modo in cui costruiamo tutto.
The Complete Internet Computer Blockchain Trinity – Bitcoin, Ethereum e Internet Computer – che segna le tre principali innovazioni nella tecnologia blockchain. Queste tre reti decentralizzate si completano a vicenda e hanno scopi diversi: Bitcoin (criptovaluta), Ethereum (contratti intelligenti) e Internet Computer (computer blockchain).
Una descrizione di Internet Computer (ICP)
Una spiegazione dell’infrastruttura della piattaforma di sviluppo e del modo in cui i contenitori software consentono ai servizi Web di raggiungere miliardi di utenti.
In vista di questa importante occasione, vogliamo offrire al pubblico una visione di altissimo livello su come funziona la rete.
Sistema nervoso in rete
Il computer Internet si basa su un protocollo di computer blockchain chiamato ICP (Internet Computer Protocol). La rete stessa è costruita da una gerarchia di elementi costitutivi. In fondo ci sono data center separati che ospitano nodi hardware specializzati. Queste macchine nodo vengono combinate per creare sottoreti. Le sottoreti ospitano contenitori software, che sono unità di calcolo interoperabili che gli utenti scaricano e contengono sia codice che stato.
Una delle cose che rende unico l’ICP è il Network Nervous System (NNS), responsabile del controllo, della configurazione e della gestione della rete.
I data center si uniscono alla rete sollecitando l’NNS, che è responsabile dell’induzione dei data center. Sebbene lo stesso NNS abbia un sistema di governo aperto, sovrintende alle autorizzazioni per partecipare alla rete. In un certo senso, svolge un ruolo equivalente a quello di ICANN su Internet, che, tra le altre cose, assegna numeri di sistema autonomi a coloro che desiderano eseguire router BGP. L’NNS esegue un’ampia gamma di funzioni di gestione della rete, compreso il monitoraggio delle macchine del nodo per discrepanze statistiche nella rete di computer Internet, che potrebbero indicare prestazioni scadenti o comportamenti difettosi.
L’NNS svolge anche un ruolo chiave nell’economia simbolica della rete. L’NNS genera nuovi token ICP (precedentemente noti come token DFN) per premiare i nodi gestiti da data center e neuroni che votano all’interno dell’NNS, è così che decide quali proposte gli vengono inviate. Quando l’NNS crea nuovi token ICP per premiare data center e neuroni, è inflazionistico.

Nel tempo, i proprietari di neuroni e data center possono prendere i loro token e riscattarli con proprietari e gestori di contenitori. I proprietari e i gestori dei contenitori prendono questi gettoni e li trasformano in cicli e li usano per caricare i loro contenitori. Quando queste cartucce eseguono calcoli o immagazzinano memoria, ad esempio, si esauriscono durante i cicli e alla fine devono essere ricaricate con più cicli per continuare a funzionare. È deflazionistico.
Sottoreti
Per comprendere il computer Internet, è necessario comprendere il concetto di sottoreti, che sono la linfa vitale dell’intera rete. Una sottorete è responsabile dell’hosting di un sottoinsieme separato di contenitori software ospitati sulla rete di computer Internet. Una sottorete viene creata riunendo macchine nodo da diversi data center in un modo controllato dall’NNS. Queste macchine del nodo collaborano tramite PKI per replicare simmetricamente i dati e i calcoli relativi ai contenitori software che ospitano.
L’NNS combina nodi di data center indipendenti creando sottoreti. Ciò consente alla matematica del protocollo ICP di garantire che le sottoreti siano a prova di manomissione e inarrestabili, utilizzando la tecnologia bizantina a tolleranza di errore e la crittografia sviluppata da DFINITY. Sebbene le sottoreti siano gli elementi costitutivi fondamentali della rete informatica complessiva di Internet, sono trasparenti per gli utenti e il software. Gli utenti e il software Canister devono solo conoscere l’identità di un Canister per richiamare le funzioni condivise.
Questa trasparenza è un’estensione dei principi fondamentali di progettazione di Internet. Su Internet, se un utente desidera connettersi a un determinato software, tutto ciò che deve fare è conoscere l’indirizzo IP della macchina su cui è in esecuzione il software e la porta TCP su cui il software sta ascoltando. Sul computer Internet, se un utente desidera chiamare una funzione, tutto ciò che deve fare è conoscere l’identità del destinatario e la firma della funzione. Nello stesso modo in cui Internet crea una connettività senza interruzioni, DFINITY ha creato un mondo perfetto per il software, in cui qualsiasi software autorizzato può chiamare direttamente qualsiasi altro software senza sapere nulla sul funzionamento sottostante della rete.
Il computer Internet fornisce anche la trasparenza della sottorete in altri modi. L’NNS può dividere e unire le sottoreti, ad esempio, per bilanciare il carico sull’intera rete. Questo è trasparente anche per i contenitori ospitati.
In questo esempio, abbiamo una sottorete immaginaria, ABC, che ospita 11 contenitori. L’NNS gli dice di separarsi. La sottorete ABC continua con i contenitori 1–6 e viene generata una nuova sottorete, sottorete XYZ, che continua con i contenitori 7-11. Nessuna delle navi interessate avrà subito un’interruzione del servizio.
Quando scarichi le lattine sul tuo computer da Internet, devi scegliere come target un tipo specifico di sottorete. In effetti, esiste una sottorete speciale che ospita l’NNS, ma non può caricarvi i suoi contenitori. Invece, dovrebbe puntare a qualche tipo di sottorete, come “dati”, “sistema” o “fiat”.

Ogni tipo di sottorete fornisce al destinatario determinate proprietà e capacità. Ad esempio, se il destinatario è ospitato su una sottorete di dati, può gestire le chiamate ma non può effettuare chiamate ad altri destinatari. Per questo avrai bisogno di una sottorete di sistema. Se vuoi che il tuo contenitore sia in grado di contenere saldi di token ICP o inviare cicli ad altri contenitori, avrai bisogno di una sottorete fiat. E per questi motivi, i contenitori di governance possono essere ospitati solo su sottoreti fiat.
Le capacità delle sottoreti sono in parte derivate dalla tolleranza ai guasti sottostante. Questa è un’area scientifica di base davvero entusiasmante che speriamo di condividere con il pubblico nel prossimo futuro, inclusa la nuova crittografia che consente all’NNS di riparare le sottoreti danneggiate.
Barche
Lo scopo di una sottorete è ospitare contenitori. I contenitori vengono eseguiti in hypervisor dedicati e interagiscono tra loro tramite un’API specificata pubblicamente. All’interno di un contenitore è presente un bytecode WebAssembly che può essere eseguito in una macchina virtuale WebAssembly e nelle pagine di memoria su cui viene eseguito. Tipicamente, questo bytecode WebAssembly sarà stato creato compilando un linguaggio di programmazione, come Rust o Motoko. Questo bytecode avrà un runtime integrato che consente allo sviluppatore di interagire facilmente con l’API.
Nota: il codice di esempio mostrato qui è pseudo-codice.
Sul computer Internet, le funzioni condivise dai destinatari devono essere richiamate in due modi. Possono essere chiamati come una chiamata di aggiornamento o una chiamata di richiesta. La differenza fondamentale è che quando si chiama una funzione come una chiamata di aggiornamento, le modifiche apportate ai dati nella memoria del contenitore vengono conservate, mentre se una funzione viene chiamata come chiamata di query, le modifiche apportate vengono ignorate. memoria di. dopo che viene eseguito.
Le chiamate di aggiornamento apportano modifiche persistenti e sono anche a prova di manomissione poiché vengono eseguite dai protocolli di elaborazione blockchain ICP su tutti i nodi della sottorete. Non sorprende che le chiamate vengano eseguite in un ordine di chiamata globale coerente, utilizzando meccanismi che consentono l’esecuzione simultanea in un ambiente di esecuzione completamente deterministico. Aggiorna tutte le chiamate in soli due secondi.
In questo esempio, l’utente invia un ordine di acquisto a una borsa valori ospitata in un container.
Le richieste, d’altra parte, non mantengono le modifiche. Qualsiasi modifica apportata alla memoria verrà eliminata dopo essere stata eseguita. Sono molto efficienti ed economici e completi in millisecondi. Questo perché non vengono eseguiti su tutti i nodi della sottorete, il che significa anche che offrono un livello di sicurezza inferiore.
In questo esempio, l’utente richiede un feed di notizie personalizzato e ottiene il contenuto appena generato quasi immediatamente.
Persistenza ortogonale
Una delle cose più interessanti del computer Internet è il modo in cui gli sviluppatori memorizzano i dati. Gli sviluppatori non devono pensare alla persistenza, scrivono semplicemente il loro codice e la persistenza avviene automaticamente. Questa è chiamata persistenza ortogonale. Questo perché il computer Internet conserva le pagine di memoria su cui viene eseguito il codice.
Forse ti starai chiedendo come funziona il tutto. Per quanto riguarda le chiamate di aggiornamento che possono mutare le pagine di memoria, i contenitori sono lettori software. Ciò significa che può esserci un solo thread di esecuzione in un contenitore alla volta.

Sebbene ci sia un solo thread di esecuzione in un Canister, le chiamate di aggiornamento cross-Canister possono essere intercalate per impostazione predefinita. Ciò accade quando le chiamate di aggiornamento effettuano chiamate di aggiornamento tra contenitori, che si bloccano, consentendo al thread di esecuzione di passare a una nuova chiamata di aggiornamento.
Al contrario, le chiamate di query non apportano modifiche persistenti alla memoria. Inoltre, consente a qualsiasi numero di thread simultanei di elaborare le chiamate di query in una cartuccia in qualsiasi momento. Queste chiamate di query vengono eseguite sullo snapshot della memoria salvato nell’ultima root di stato completata.
Infine, nessuna discussione sulle barche sarebbe completa senza menzionare che le barche possono creare nuove barche e che le barche possono diramarsi. È possibile creare una nuova cartuccia semplicemente specificando il bytecode WebAssembly e le pagine di memoria iniziano vuote. Quando un contenitore si biforca, viene creata una copia appena generata, identica alle pagine di memoria che contiene. Il fork è molto potente quando si creano servizi Internet scalabili.
Scalabilità
Ora arriva una spiegazione di alto livello dell’evoluzione dei servizi Internet. I jackpot hanno limiti massimi sui diversi tipi di capacità. Ad esempio, un contenitore può memorizzare solo 4 GB di pagine di memoria a causa delle limitazioni nelle implementazioni di WebAssembly. Per questo motivo, quando vogliamo creare servizi Internet scalabili fino a miliardi di utenti, dobbiamo utilizzare architetture multi-container.
Ci auguriamo che sia sufficiente creare un contenitore speciale, fare molte copie del contenitore e quindi frammentare il contenuto dell’utente tra i diversi contenitori per creare un servizio Internet in grado di scalare. Sfortunatamente, questa architettura è troppo semplice per diversi motivi.
È vero che ogni contenitore aggiuntivo aumenta la capacità di memoria complessiva. È anche vero che ogni cartuccia aggiuntiva aumenta le prestazioni complessive di aggiornamento e richiamo delle query. Ma non possiamo aumentare le richieste di chiamata di query per contenuti utente specifici. Dobbiamo anche ribilanciare il contenuto degli utenti ogni volta che aumentiamo la capacità del sistema aggiungendo più frammenti del contenitore, e questa non è davvero una grande architettura edge. Inoltre, non esiste un modo ovvio per gestire le chiamate di richiesta agli utenti finali dai mirror vicini a loro. Avremo bisogno sia di barche di ingresso che di barche a fondo.
Il computer Internet fornisce funzionalità interessanti per connettere gli utenti finali ai contenitori front-end. Uno di questi consente l’assegnazione di nomi di dominio a diversi contenitori front-end tramite NNS. Quando un utente finale desidera risolvere questo nome di dominio, il computer Internet esegue la scansione di tutti i nodi di replica in tutte le subnet che ospitano i contenitori Front End e restituisce gli indirizzi IP dei nodi di replica più vicini. Ciò si traduce nell’utente finale che esegue chiamate di query sulle repliche vicine, riducendo la latenza di rete intrinseca e migliorando l’esperienza utente, offrendo i vantaggi dell’edge computing senza una rete di distribuzione dei contenuti.
Per ottenere il massimo da questa funzionalità, abbiamo bisogno di un’architettura classica che coinvolga contenitori front-end e contenitori di dati back-end. In questo esempio, un browser Web desidera caricare un’immagine del profilo.
Innanzitutto, il browser Web verrà mappato a un contenitore front-end in esecuzione su una sottorete con un nodo vicino. Il browser web invierà una richiesta di chiamata di richiesta per recuperare la foto su questo nodo vicino.
Il contenitore front-end effettuerà una richiesta di chiamata di query tra contenitori al contenitore di dati che contiene la foto.
Se la risposta alla chiamata della query restituita dal contenitore del data warehouse include contenuto statico, come una foto, i dati potrebbero essere memorizzati nella cache. In questi casi, il nodo di replica che esegue la chiamata alla query del contenitore front-end può inserire la risposta dalla chiamata alla query nella sua cache delle query.
Ovviamente, il meccanismo per la memorizzazione nella cache delle chiamate di richiesta è completamente trasparente al codice del contenitore front-end. Dopo che il contenitore front-end chiamato dall’utente ha raccolto tutte le informazioni necessarie, può restituire il contenuto, tramite una risposta a una chiamata di richiesta o tramite un endpoint HTTP.

Nel tempo, le cache delle query dei nodi accumulano contenuto statico e generano dati di interesse per gli utenti nelle vicinanze, fornendo loro un’esperienza utente migliore e più veloce. In questo modo, l’architettura edge nativa del computer Internet fornisce i vantaggi di una rete di distribuzione dei contenuti, ma senza che gli sviluppatori debbano fare nulla di speciale e senza bisogno di aiuto, un servizio proprietario separato.
Per le chiamate di aggiornamento, l’architettura classica adotta un approccio diverso. Gli aggiornamenti al contenuto e ai dati di un utente devono essere serializzati per evitare problemi come aggiornamenti mancanti. Questo di solito si ottiene assegnando un utente a uno specifico contenitore front-end semplicemente digitando il suo nome utente, ad esempio.
Una volta che una UX / UI in esecuzione in un browser Web o smartphone determina quale contenitore front-end è responsabile del coordinamento delle modifiche a determinati contenuti o dati, può modificare tale contenuto o dati inviando una chiamata di aggiornamento aggiornata alla sua interfaccia standard.
Questo contenitore front-end in genere effettua più chiamate di aggiornamento tra contenitori per apportare le modifiche necessarie.
Apri servizi Internet
Per riassumere, discutiamo della progettazione di un servizio Internet aperto utilizzando la nostra architettura a due livelli con contenitori front-end e contenitori di dati back-end. Prima di tutto, quando scrivi il codice del contenitore front-end, ti semplificherà la vita utilizzando la classe di libreria esistente chiamata BigMap.
BigMap può memorizzare exabyte di dati e puoi scrivere oggetti su di esso utilizzando una singola riga di codice. Questa architettura si evolverà in modo trasparente e dinamico grazie alla presenza di contenitori front-end e contenitori di dati per distribuire la responsabilità per gli oggetti assegnati a un contenitore tra due contenitori.
Infine, per creare un vero servizio Internet aperto, assegnerai la responsabilità di tutti i tuoi destinatari a un destinatario simbolizzato di un governo aperto. Se sei un imprenditore, raccoglierai fondi per lo sviluppo vendendo all’inizio alcuni di questi token di governance. E probabilmente progetterai sistemi che incentiveranno il tuo servizio Internet nella fase iniziale fornendo loro token di governance per migliori effetti di rete e vincenti.

 Bitcoin
Bitcoin  Ethereum
Ethereum  Tether
Tether  BNB
BNB  XRP
XRP  USDC
USDC  Solana
Solana  Figure Heloc
Figure Heloc